Časové řady
Nejenom malé datové soubory, ale i velké soubory dat mohou být zkresleny
velkým rozptylem, nehomogenitou a proto neodpovídají normálnímu rozdělení. Z toho důvodu i tyto datové soubory, jakými jsou beze sporu
časové řady, nelze uspokojivě vyhodnotit standardními metodami. Jejich množství hodnot je velké, ale vyhodnocení může být problematické.
Díky metodě robustních distribučních funkcí je možné i tato data efektivně vyhodnotit.
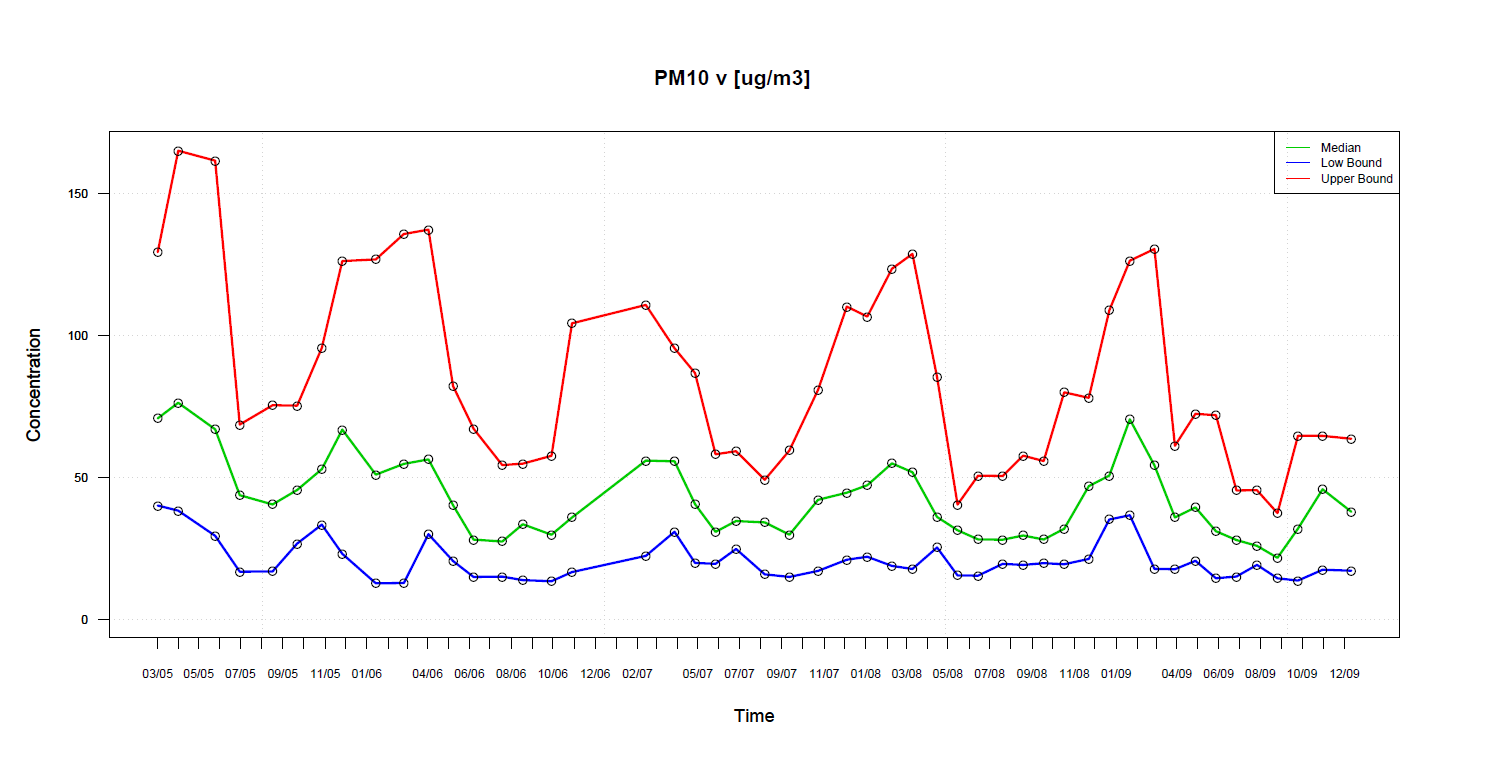
Z robustních distribučních funkcí zjistíme důležité hodnoty, jako jsou dolní mez, horní mez a medián a jak jsou rozloženy v čase v celém souboru.
Jak to pracuje? Vezměme interval hodnot (například 10 po sobě jdoucích vzorků) vypočítáme distribuční funkci a posunem intervalu s překryvem např. pěti hodnot tak vypočítáme
postupně další distribuční funkce pro zjištění tří reprezentativních veličin z každého intervalu.
Získáme tak průběh, který reprezentuje časovou souslednost dolních, horních mezí a mediánu za celé období měření.
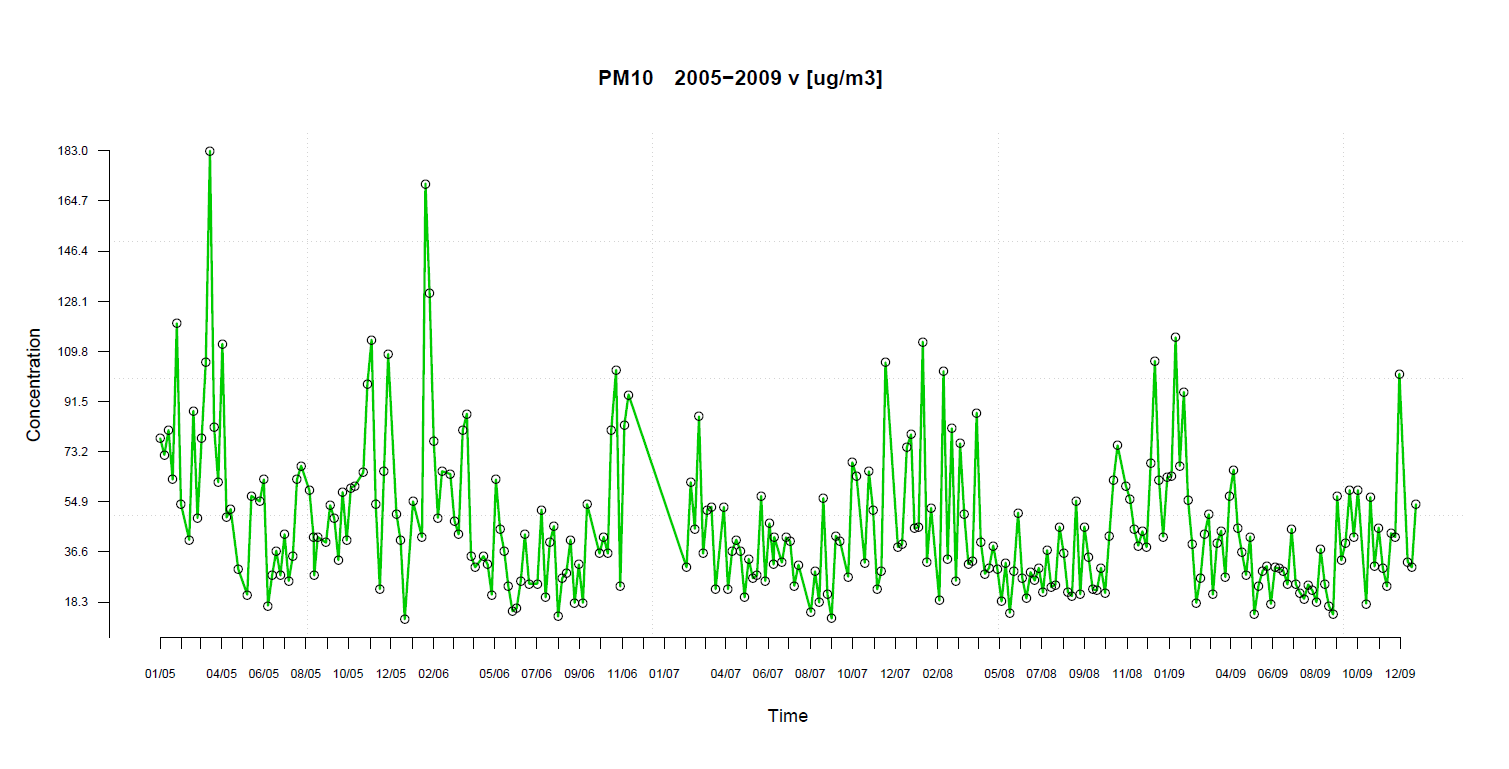
Typický příklad je z oblasti monitoringu ovzduší např. veličiny polétavého prachu PM10. Na prvním obrázku
jsou původní naměřená data a druhý obrázek je jejich vyhodnocení. Pro porovnání s ostatními hodnotami (např. koncentrace fenantrenu)
ve stejném časovém období, lze vyhodnotit souvislost mezi dvěma i více hodnotami zároveň. V tomto případě souvislost mezi koncentrací PM10
a Fenantrenu v dané lokalitě a daném časovém rozmezí.